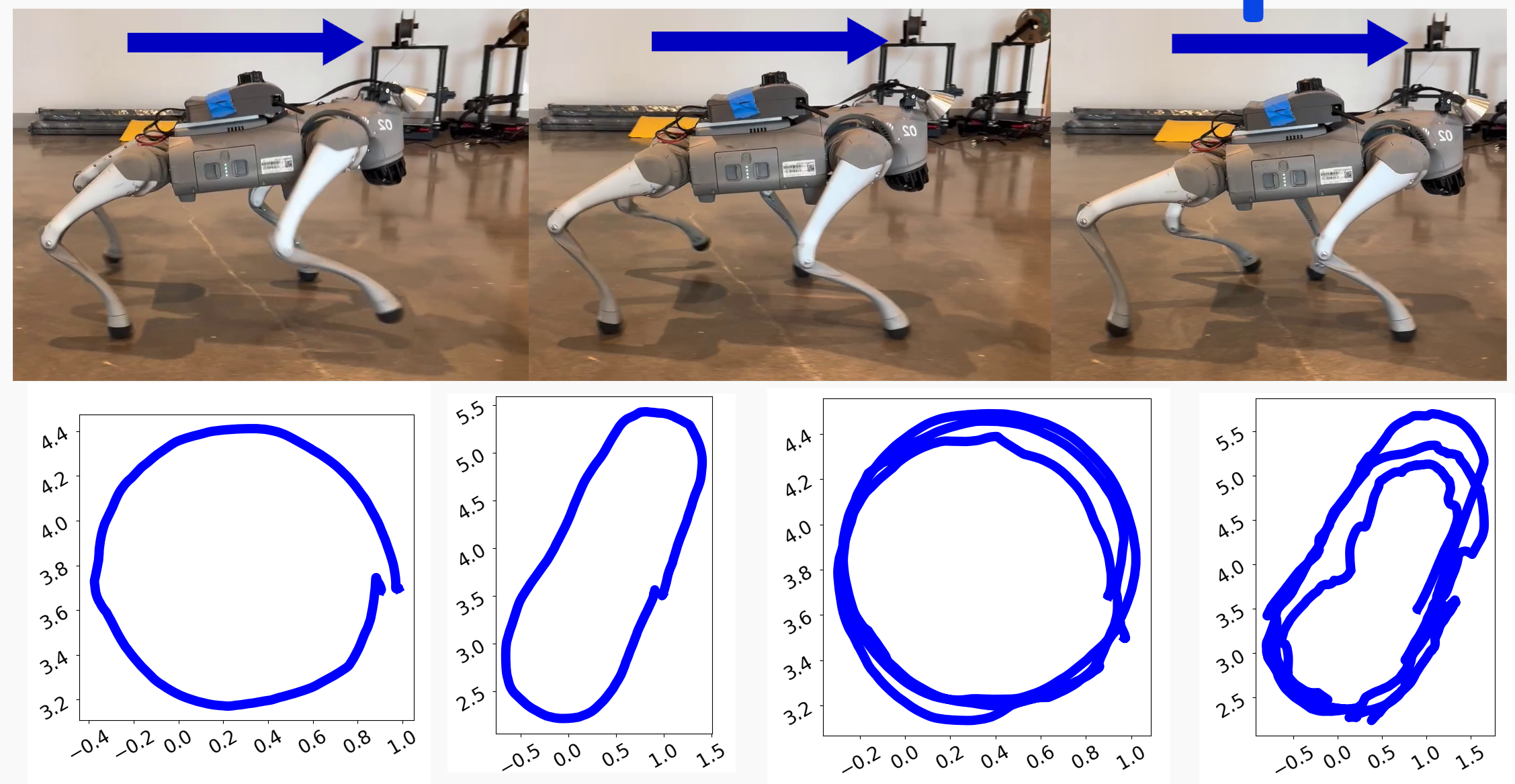
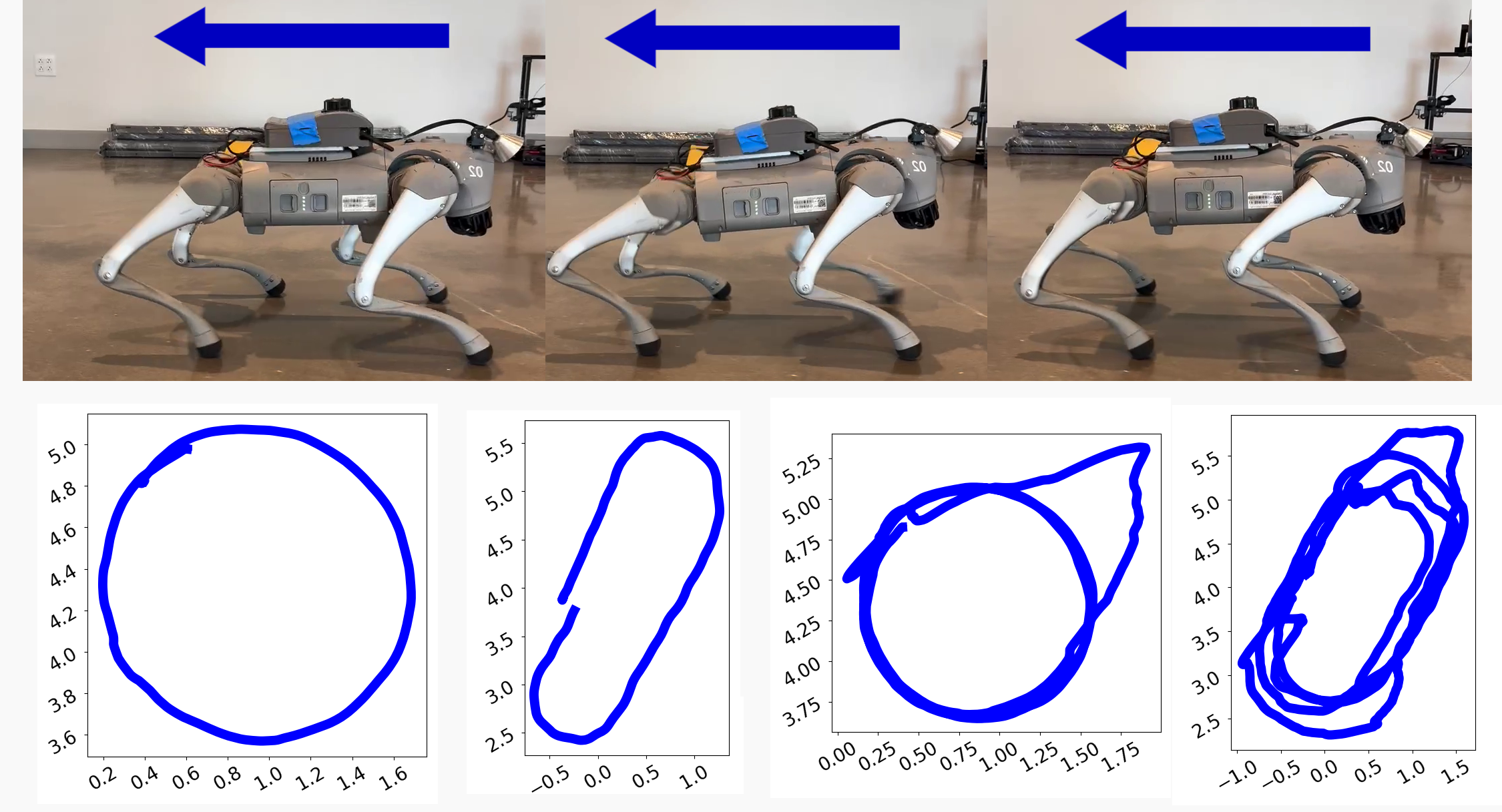
Covariance Output of Legolas
Legolas outputs a predicted instantenous velocity and variance for each prediction. We demonstrate the covariance output of Legolas on two of the above rollouts.
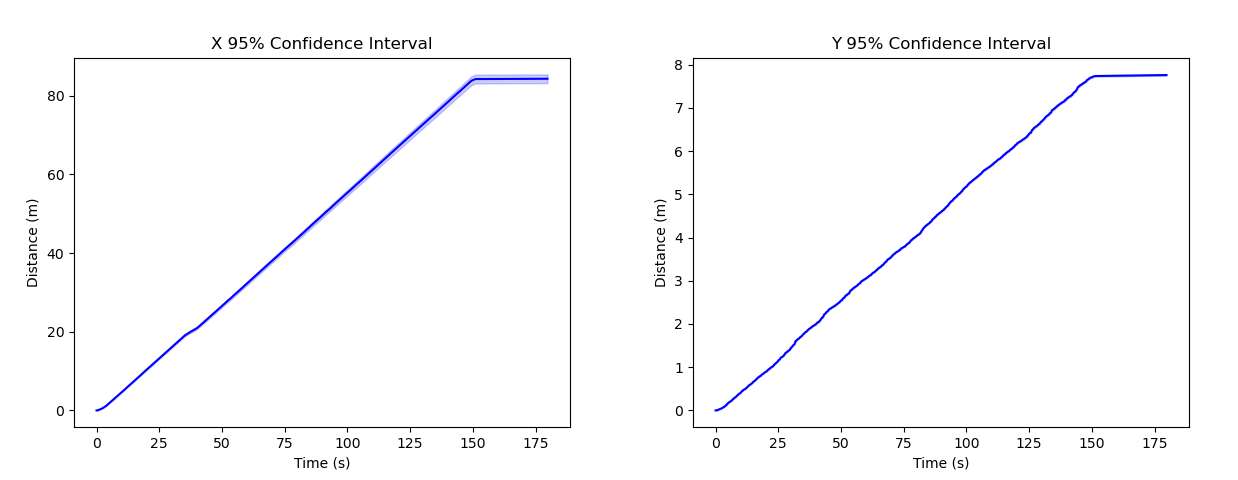
Building
Analysis: In this scenario, the |Y| displacement and variance are much smaller than the |X| displacement. This matches what is expected as the robot is moving forward, and this would be dominated by an |X| displacement with a smaller |Y| displacement from swaying. After completing the first hallway, the robot turns sharply and causes a dip in displacements, which are matched with a dip in variance as the robot is moving slower. The lower variances when the robot is moving slower can also be observed at the start of the plot as the robot starts to move.
Building 95% Confidence Intervals
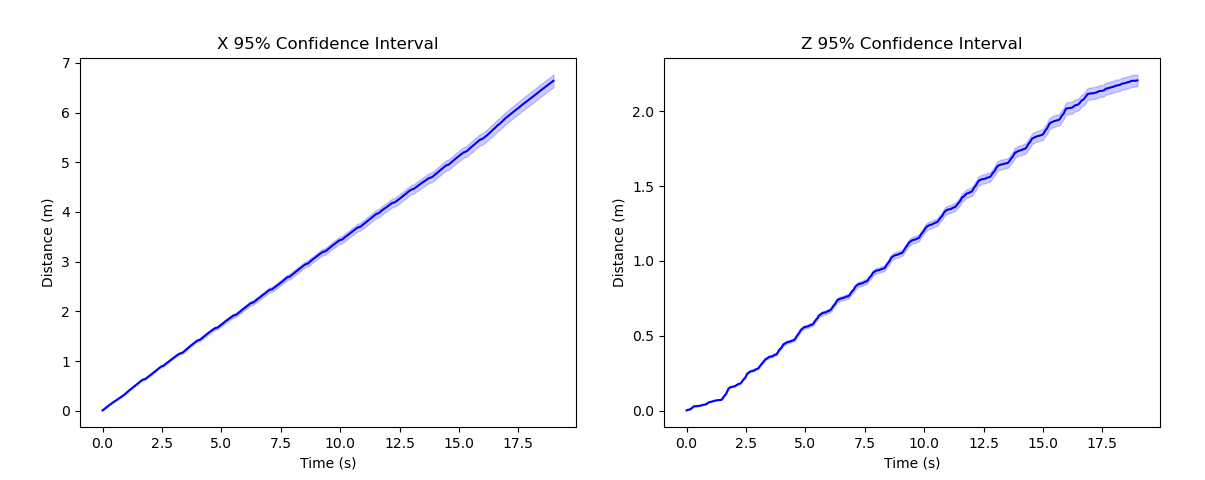
Stairs
Analysis: While going up the stairs the |X| and |Z| displacements are very cyclical with their peaks being matched with peaks in variance occurring wherever the displacement changes quickly. When the robot reaches the new floor, variances for |X| and |Z| decrease as there is less instantaneous motion.
Stairs 95% Confidence Intervals